

MM-LLMs综述(腾讯)
https://arxiv.org/pdf/2401.13601
MM-LLMs综述
摘要
首先,我们概述了模型架构和训练流程的通用设计形式。
随后,我们引入了涵盖126个MM-LLMs的分类体系,每个模型都具有特定的结构。
接着,我们评估了选定MM-LLMs在主流基准上的表现,并总结了关键的训练方法,以提升MM-LLMs的效能。
最后,我们探讨了MM-LLMs的未来发展方向,并维持一个实时跟踪网站,以监控该领域的最新进展
1. 引言
随着模型和数据集规模的扩展,传统的多模态模型在训练过程中产生了巨大的计算成本,尤其是当采用大规模的模型和数据集进行端到端训练时。认识到多模态研究是在各种模态的交叉点上进行的,一种合理的方法是利用现成的预训练单模态基础模型,特别强调强大的大型语言模型 (LLM)。从而催生了MM-LLM这一领域的出现。
LLMs 具备强大的语言生成、零样本迁移和上下文学习(ICL)等优势。
鉴于不同模态的基础模型是分别预训练的,MM-LLMs 面临的核心挑战在于如何有效地将 LLMs 与其他模态的模型连接,以实现协同推理。该领域的主要研究重点在于通过多模态预训练( ...

MICCAI2024(2)-BIRD
论文地址:https://papers.miccai.org/miccai-2024/paper/1279_paper.pdf
代码地址:https://github.com/ShawnHuang497/BiRD
BiRD
摘要与引言
生物医学领域的语言和文本不同于自然语言与自然文本,导致常规的视觉助手在生物医学领域表现不佳。这些助手要么无法回答生物医学问题,要么更糟糕的是,提供不准确的回答或完全虚构的信息。
目前生物医学领域的MMLM研究主要集中于图像描述和VQA,在“refer”和“ground”能力方面仍存在显著的缺失,如图1所示:
“refer”要求模型能够准确地理解特定区域的语义内容
“ground”则需要模型根据提供的语义描述对区域进行定位
图 1:BiRD 为生物医学中的多模式大语言模型提供了复杂的refer和ground功能
这些细粒度的多模态能力对于智能生物医学助手与患者之间的交互过程和生物医学教育至关重要。这项能力不仅使信息交换过程更加直观,还显著提高了信息交换的准确性和效率。在生物医学领域缺乏多模态细粒度交互数据集是阻碍这一能力发展的主要因素。
基于此, ...

LLaVA(2)-Improved Baselines with Visual Instruction Tuning
论文地址:https://arxiv.org/abs/2310.03744
论文代码:https://github.com/haotian-liu/LLaVA
LLaVA-Improved Baselines with Visual Instruction Tuning(V1.5)
摘要
本文在LLaVA框架下,首次系统地研究了多模态模型的设计选择,研究是在受控条件下进行的。研究表明,LLaVA中的全连接视觉-语言连接器具有出色的性能和数据效率。在此基础上,通过以下简单改进建立了更强的基准模型:
使用CLIP-ViT-L-336px作为视觉编码器,并配备MLP投影层;
添加面向学术任务的VQA数据集,并优化响应格式提示。
改进后的模型在11项基准测试中达到了最新的性能水平。最终的13B模型仅使用了120万公开数据,在单台8卡A100机器上约1天即可完成训练。此外,我们还在多模态模型的一些开放性问题上进行了初步探索,包括更高分辨率输入的扩展、组合能力以及模型幻觉等问题。
1. 引言
大规模多模态模型(LMMs)在研究领域中变得越来越流行,因为它们是通用型助手的关键构建模块。最近 ...

LLaVA(1)-Visual Instruction Tuning
论文 Paper: https://arxiv.org/abs/2304.08485
代码 GitHub: https://github.com/haotian-liu/LLaVA
参考:
https://zhuanlan.zhihu.com/p/622907299
https://hackmd.io/@YungHuiHsu/HyMgBbjSa#Multimodal-LLaVA鍊成術-視覺指令調節-Visual-Instruction-Tuning
LLaVA-Visual Instruction Tuning
摘要
使用机器生成的Instruction followling数据对大规模语言模型(LLM)进行指令调优,已经证明可以提高它们在新任务上的zero-shot能力,但这一思想在多模态领域的探索较少。
本文首次尝试使用仅支持语言的GPT-4生成多模态语言-图像Instruction followling数据。通过对这些生成的数据进行指令调优,我们提出了LLaVA:大型语言和视觉助手,这是一个端到端训练的大型多模态模型,结合了视觉编码器和LLM,旨在进行通用的视觉和语言理解。
...

MICCAI2024(1)-PMC-CLIP
论文地址:https://arxiv.org/abs/2303.07240
论文代码:https://github.com/WeixiongLin/PMC-CLIP/
PMC-CLIP(MICCAI 2024)
摘要
PMC-OA,一个包含160万图像-描述对的生物医学数据集,数据来自PubMed Central的开放获取子集,规模是之前数据集的8倍。PMC-OA涵盖了多种模式和疾病,绝大多数图像-描述对在更细的层级(如子图和子标题)上对齐。
在PMC-OA上预训练的CLIP风格模型PMC-CLIP,在多个下游任务上实现了当前最优的表现,包括ROCO上的图像-文本检索、MedMNIST图像分类和医学问答(VQA),例如,在图像-文本检索任务中R@10提升了8.1%,在图像分类任务中的准确率提升了3.9%。
1 引言
生物医学领域在基础模型方面的进展相对缓慢,原因有二:
需要专家标注的专业性要求
数据隐私的限制
因此本文提出了使用公开科学论文来构建一个大规模、高质量的生物医学图像-文本数据集的初步研究,且仅需极少的手动操作。
我们从PubMed Central(美国国立卫生 ...
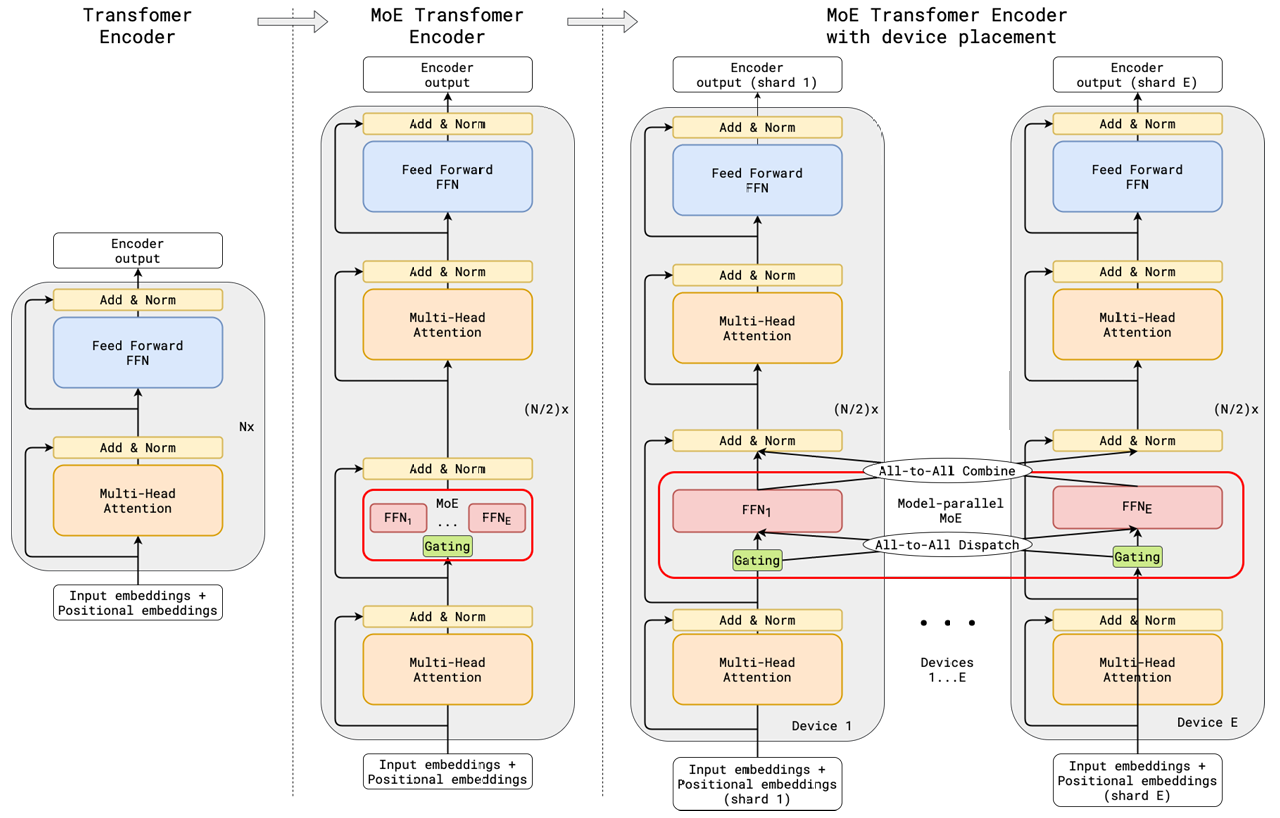
大模型系列(三)- MoE:混合专家模型
DeepSeed提出的Moe原论文:2006.16668
参考:图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(原理篇) - 知乎
混合专家模型 (MoE) 详解 - 知乎
大模型系列(三)- MoE:混合专家模型
1. 什么是MoE
MoE(Mixers of Experts)混合专家模型的理念起源于1991年的论文**Adaptive Mixture of Local Experts**。这里不做介绍,仅讨论现代LLM中的MoE.
Switch Transformer 论文中的 MoE Layer
GShard 论文中的 MoE Transformer Encoder
1.1 MoE原理
原理:将输入通过门控Gate分配给适合处理这类输入的"专家"Experts,而不是把输入交给所有的"专家"Experts进行处理。通过这种方式减小计算量,在有限的计算资源预算下,用更少的训练步数训练一个更大的模型。(只是简单概述,细节后面会讨论)。
优势:
与稠密模型相比, 预训练速度更快
与具有相同参数数量的模型相比 ...
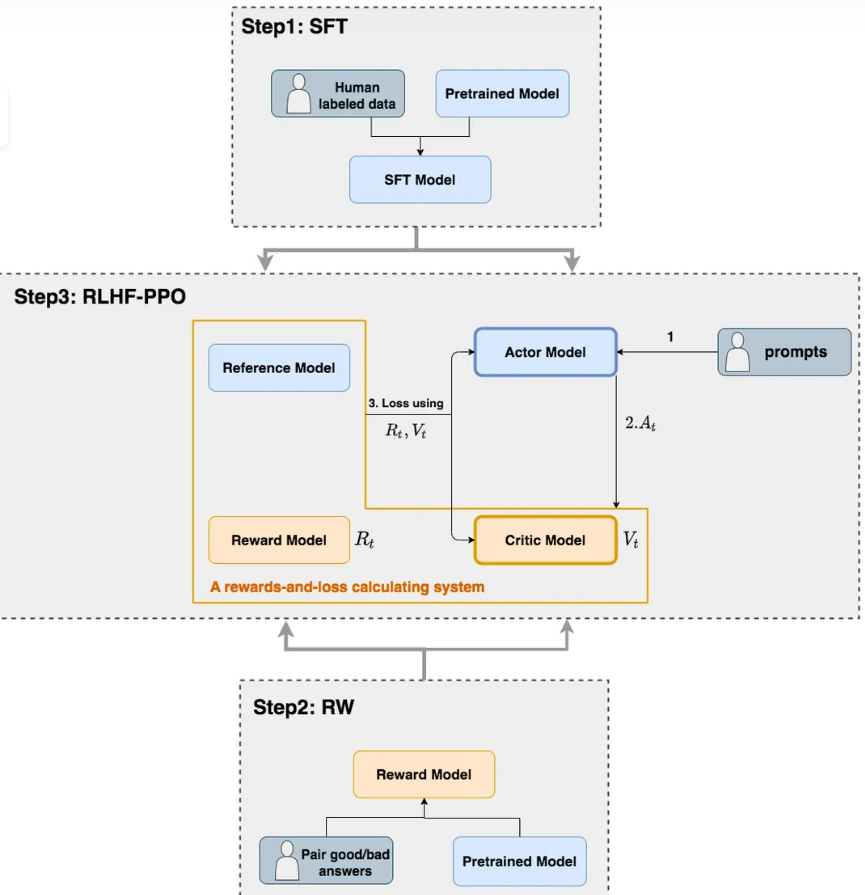
大模型系列(二)- RLHF:基于人类反馈的强化学习
参考:图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 - 知乎
大模型系列(二)- RLHF:基于人类反馈的强化学习
Reinforcement Learning from Human Feedback
RLHF有人说提升很大,也有人说效果不明显,究其根本还是系统链路太长自由度太高,不像SFT一样可以通过数据配比、prompt、有限的超参数来可控地调整效果。
也正是因为它的自由度、以目标为导向的学习范式和性价比更高的标注成本,业内往往认为它的上限更高。认为scalable的RLHF(不局限于PPO)就是下一步的大突破所在。
大语言模型的RLHF,实际上是模型先试错再学习的过程。 我们扮演着老师的角色,给出有趣的问题,而模型则会像小学生一样,不断尝试给出答案。模型会对着黑板写下它的答案,有时候是正确的,有时候会有错误。我们会仔细检查每一个答案,如果它表现得好,就会给予它高声赞扬;如果它表现不佳,我们则会给予它耐心的指导和反馈,帮助它不断改进,直到达到令人满意的水平。
1. RLHF介绍
1.1 强化学习整体流程
强化学习的两个实体:智能体(Agent)与环境(Env ...
多模态系列(七)- 总结
转载自:多模态系列论文----最详细的多模态论文总结(BLIP、BEIT、CoCa等)_多模态大模型系列论文-CSDN博客
多模态系列(七)- 总结
1. 多模态概述
多模态指的是多种模态的信息数据,包括:文本、图像、视频、音频等。多模态任务是指需要同时处理两种或多种不同类型的数据的任务。近年来,随着深度学习技术的发展,多模态任务取得了显著的进步。特别是VIT(Vision Transformer)和CLIP(Contrastive Language–Image Pre-training)这两种基于Transformer模型的方法,极大地推动了多模态研究的发展。相比于传统的基于CNN(Convolutional Neural Network)的方法,Transformer能够对不同模态的数据进行统一建模,包括参数共享和特征融合。这极大地降低了多模态任务的复杂性和计算成本。
本文主要关注文本、图像两种模态数据的处理。
常见任务
图像描述(image captioning) :对给定图像生成描述性说明或生成字幕。
视觉定位(visual grounding):在给定的图像中定位具有指 ...
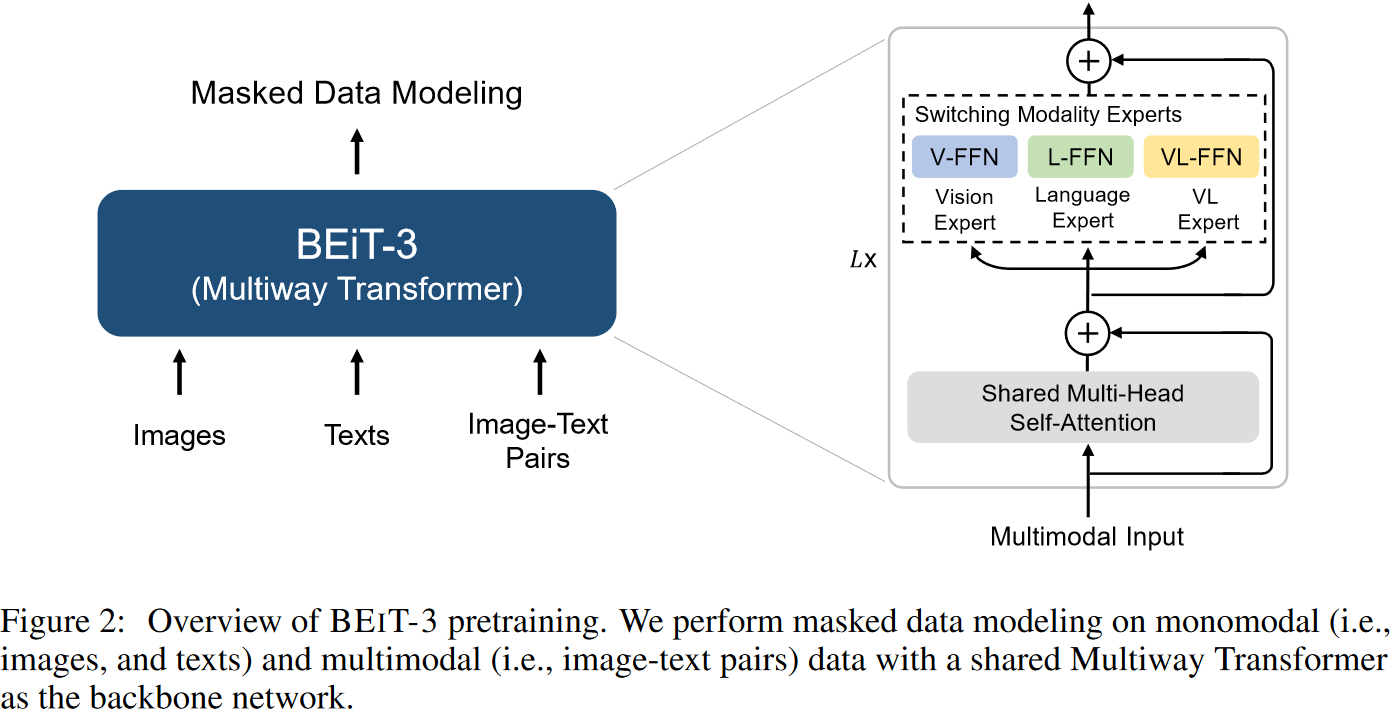
多模态系列(六)- BEiTv3
论文地址:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
论文代码:BEiT-3
转载自:多模态系列论文–BEiT-3 详细解析_beitv3 github-CSDN博客
多模态系列(六)- BEiTv3
摘要
BEiTv3的目标非常明确,就是想做一个更大一统的框架,不论是从模型上统一,而且从训练的目标函数上要统一,还有模型大小,数据集大小,如何scale也要统一,作者称之为Big Convergence。BEiTv3就是把图像也看成了是一种语言(这就是他们题目的意思叫做Image as a Foreign Language),文章把Image叫做Imagelish,文本叫做English,然后把图像文本对叫做Parallel Sentence。因为不论是图像还是文本都可以用Mask Modeling去做,所以就不需要ITC,ITM ,Language Modeling或者Word Patch Alignment等各种Loss,只用一个Loss----- M ...
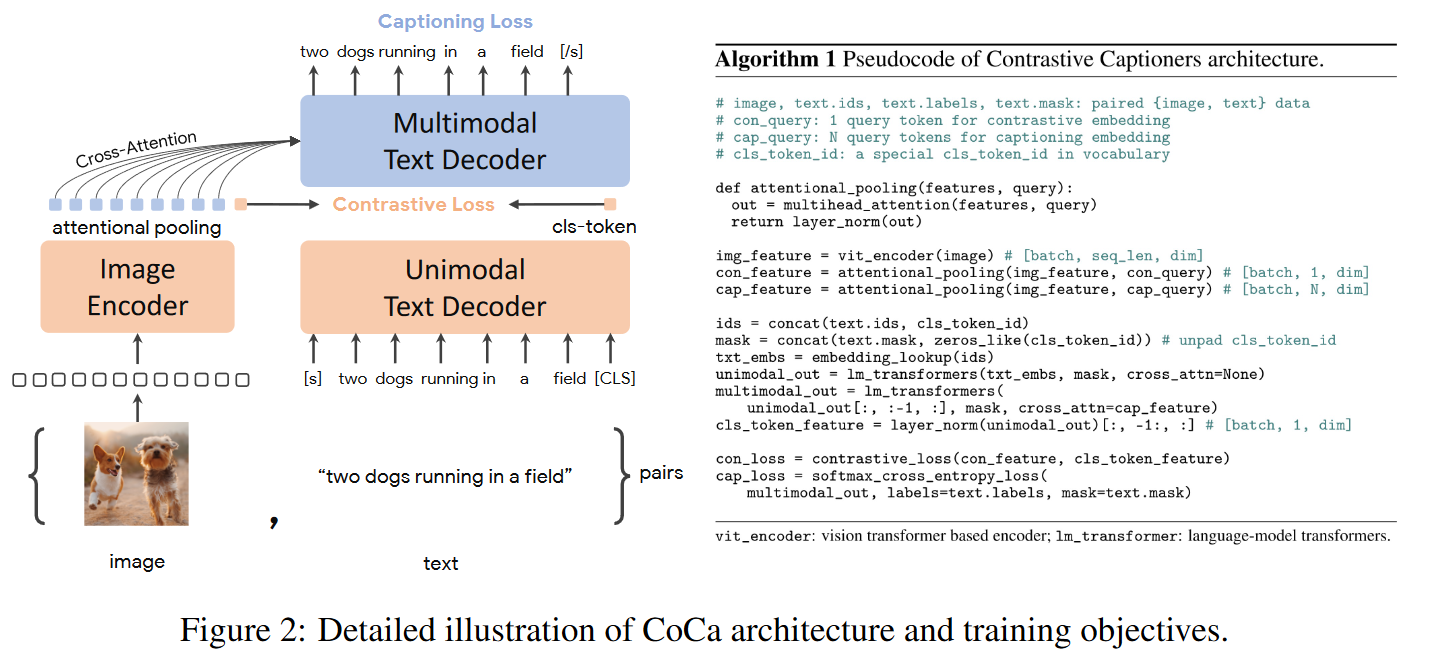
多模态系列(五)- COCA
论文地址:CoCa: Contrastive Captioners are Image-Text Foundation Models
代码地址:CoCa
转载自:多模态系列论文–CoCa 详细解析_coca paper-CSDN博客
多模态系列(五)- COCA
1 摘要
CoCa代表Contrastive Captioners的缩写,代表模型用两个目标函数训练出来的,一个是Contrastive Loss,一个是Captioning Loss。本文因为数据集更大,模型也更大,所以它的效果很好,在多模态所有的任务均SOTA,而且在单模态里,在ImageNet上也得到了90以上的Top1准确度,在视频动作识别领域,在Paper with Code上CoCa在K400、K600、K700这些数据集上排名前三。
2. 网络结构
CoCa是ALBEF的一个后续工作,它与ALBEF的模型类似,左边是一个Image Encoder,右边是一个Text Decoder,注意,这里是Decoder不是Encoder。从左右来看还是左边图像分支,右边文本分支,文本分支分两部分,下面用来抽取Uni ...