
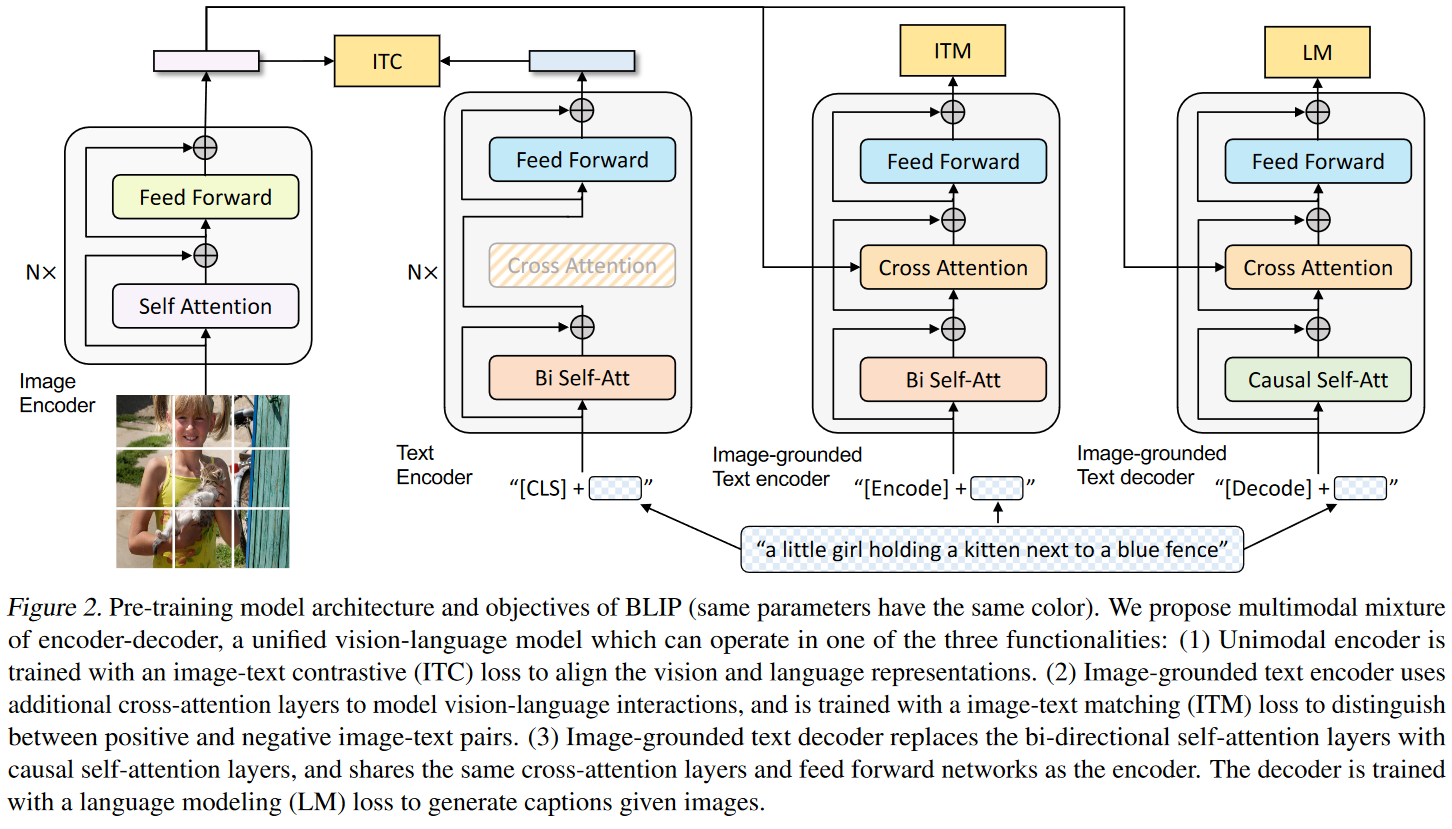
多模态系列(四)- BLIP
论文地址:arxiv.org/pdf/2201.12086
论文代码:https://github.com/salesforce/BLIP
转载自:多模态系列论文–BLIP 详细解析_blip论文-CSDN博客
多模态系列(四)- BLIP
1. 研究动机及本文贡献
从模型角度:最近的一些方法通常有2种模型实现方式,1)Transformer Encoder结果的模型,比如Clip、ALBEF,2)Transformer Encoder、Decoder结构的模型,比如SimVLM。第一种Encoder Only的模型无法直接运用到Text Generation的任务,比如图像生成字幕,因为它只有编码器没有解码器,需要加一些模块做Text Generation的任务;第二种Encoder、Decoder虽然有Decoder可以做生成的任务,但因为没有一个统一的框架,所以它不能直接用来做图像文本检索(Image Text Retrieval)的任务,因此需要提出一个统一的框架,用一个模型把所有的任务都解决。BLIP这篇论文就是(利用了很多VLMO里的想法)把模型设计成一个灵活的框架,从 ...
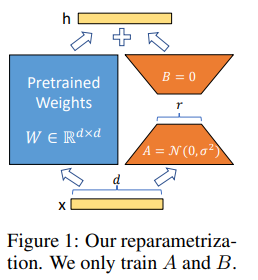
大模型系列(一)- LoRA
论文地址:arxiv.org/pdf/2106.09685
论文代码: https://github.com/microsoft/LoRA.
转载自:图解大模型微调系列之:大模型低秩适配器LoRA(原理篇) - 知乎
图解大模型微调系列之:大模型低秩适配器LoRA(源码解读与实操篇) - 知乎
大模型系列(一)- LoRA
1. 全参数微调
全量微调指的是,在下游任务的训练中,对预训练模型的每一个参数都做更新。
缺点:训练代价昂贵,在微调中发现有bug时覆水难收。
启发:由于模型在预训练阶段已经吃了足够多的数据,收获了足够的经验,因此我只要想办法给模型增加一个额外知识模块,让这个小模块去适配我的下游任务,模型主体保持不变(freeze)即可。
2. Adapter Tuning与Prefix Tuning
Adapter Tuning与Prefix Tuning是Lora出现之前两种主流的微调方法
2.1 Adapter Tuning
Adapter Tuning的方法有很多种,以arxiv.org/pdf/1902.00751为例,该篇文章是LoRA论文中提及这项技术时所引用 ...
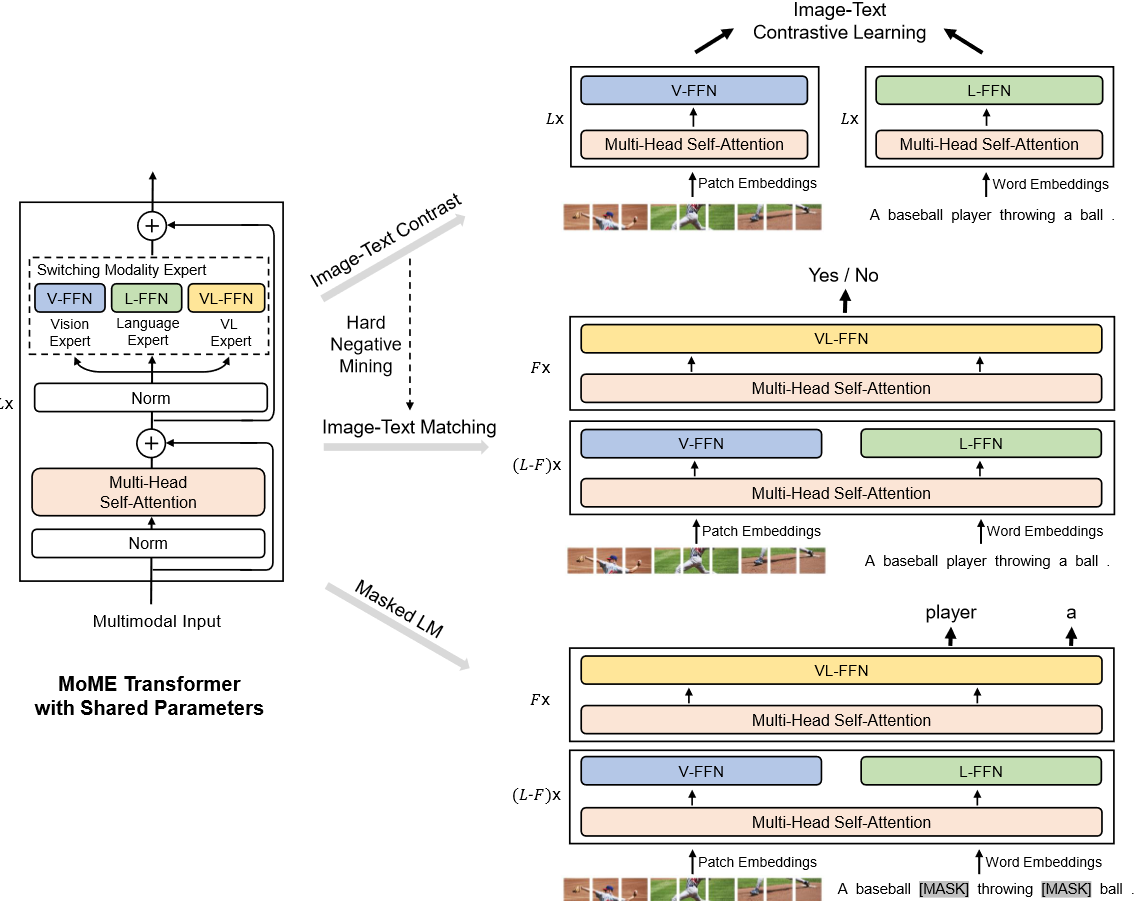
多模态系列(三)- VLMO
论文地址:VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
论文代码:VLMO
转载自:[多模态系列论文–VLMO 详细解析-CSDN博客](https://blog.csdn.net/lansebingxuan/article/details/131721728)
多模态系列(三)- VLMO
1. 研究动机
现在多模态学习领域有两个主流的模型结构:
双塔结构:
图像有一个模型,文本有一个模型,双塔完全分开,互不干扰,模态之间的交互用非常简单的Cosine Similarity来完成,比如CLIP Align这种dual-encoder。
结构优点:对检索任务极其有效,因为它可以提前把特征都抽好,接下来直接算Similarity矩阵乘法就可以,极其适合大规模的图像文本的检索,非常具有商业价值。
结构缺点:只计算Cosine Similarity无法做多模态之间深度融合,难一些的任务性能差。
单塔结构:
Fusion Encoder的方式,先把图像和文本分开处理一下,但是当做 ...
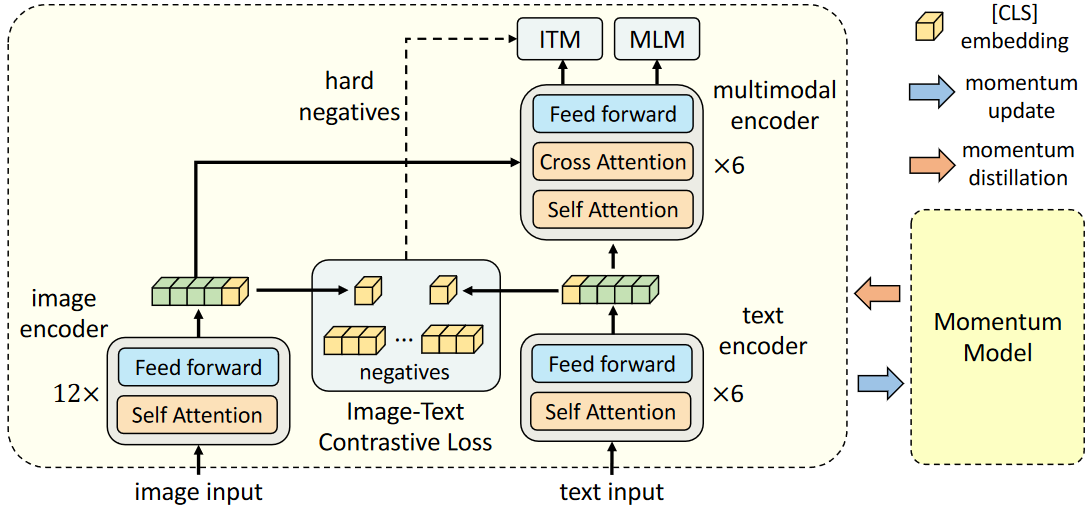
多模态系列(二)- ALBEF
代码地址:ALBEF
原文链接:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
转载自:多模态系列论文–ALBEF 详细解析-CSDN博客
多模态系列(二)- ALBEF
摘要
最近图像文本的大规模的特征学习非常火爆,大部分已有的方法都是用一个Transformer模型作为多模态的一个编码器,同时编码视觉的Token和文本的Token,视觉Token就是视觉特征,一般是region-based的图像特征,,即目标检测模型提取出来的特征。
本文贡献1–ALign BEfore Fuse:
ViLT和ALBEF都认为不需要目标检测的模型,但ViLT只是说用了目标检测模型以后速度太慢,希望推理时间变得更快,但是ALBEF分析认为使用预训练的目标检测器之后,视觉特征和文本特征无法align对齐,因为目标检测器是提前训练好的,只抽取特征,没有再进行end-to-end的训练,所以导致视觉特征和文本特征可能相隔很远,此时将两个特征同时送入多模态的编码器之后,编码器 ...
多模态系列(一)- 介绍
多模态系列(一)- 介绍
Transformer Encoder
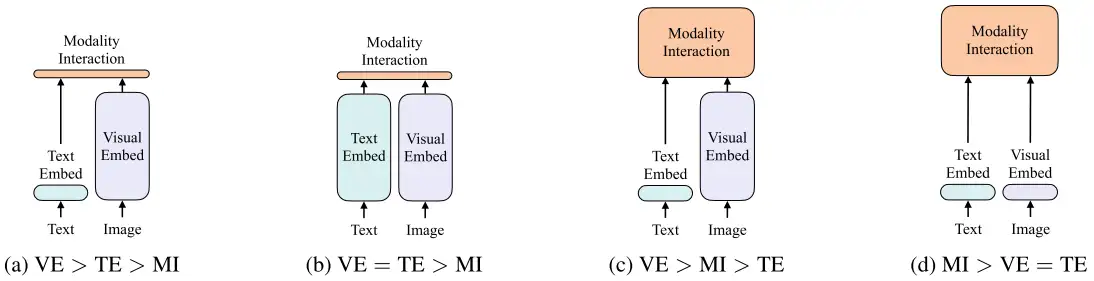
上图是早期工作的一个简单总结:
图 (a) 是VSE或者VSE++的架构,它们的文本端就是直接抽一个文本特征,但是它们的视觉端非常大,需要的计算量非常多,因为它是一个目标检测器。当得到了文本特征和视觉特征之后,它最后只能做一个很简单的模态之间的交互,从而去做多模态的任务。
图(b)是CLIP的结构,视觉端和文本端都用同等复杂度的encoder进行特征提取,再做一个简单的模态交互,结构优点是对检索任务极其有效,因为它可以提前把特征都抽好,接下来直接算Similarity矩阵乘法就可以,极其适合大规模的图像文本的检索,非常具有商业价值。缺点是只计算Cosine Similarity无法做多模态之间深度融合,难一些的任务性能差。
图(c)是Oscar或者ViLBERT、Uniter采用的架构,因为对于多模态的任务,最后的模态之间的交互非常重要,只有有了模态之间更深层的交互,VQA、VR、VE这些任务效果才会非常好,所以他们就把最初的简单的点乘的模态之间的交互,变成了一个Transformer的Encoder,或者变成别 ...
CLIP论文精读
代码地址:https://github.com/OpenAI/CLIP.
原文链接:[2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org)
参考:[医学多模态融合] 医学图像 + 文本数据 多模态模型发展及预训练模型应用_多模态模型复现 作业 课程设计-CSDN博客
笔记详情 (bilibili.com),李沐论文精读系列四:CLIP和改进工作串讲,
CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili
CLIP:利用自然语言监督信号去学习一个迁移性能好的视觉网络
前言
模型结构
(1)模型的输入是image和text的配对,image encoder即可以是ResNet也可以是ViT。假设每个traning batch里有n个image-text pair,那么会分别得到n个图片特征和n个文本特征,然后在这些特征上做对比学习。对于对比学习而言,需要正样本和负样本,正样本就是配对的image-text pair,也就是特征矩阵中对角线的部 ...
DDPM论文精读
原文链接:https://arxiv.org/abs/2006.11239
DDPM论文精读
Agent Attention论文精读
代码地址:https://github.com/LeapLabTHU/Agent-Attention
原文链接:[2312.08874] Agent Attention: On the Integration of Softmax and Linear Attention (arxiv.org)
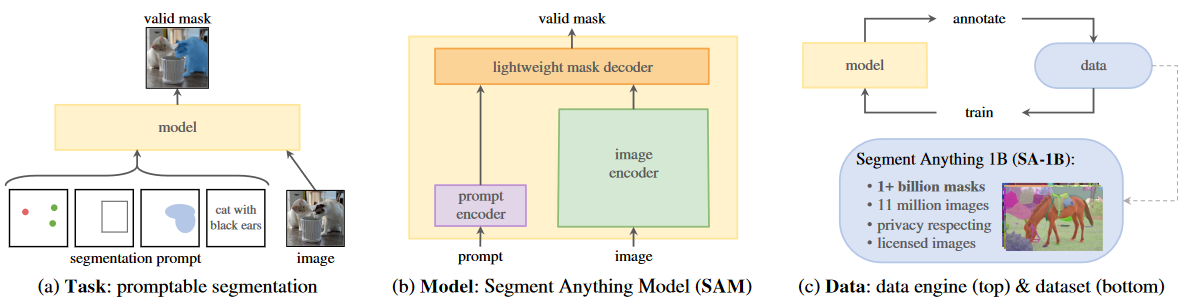
语义分割与SAM精读
原论文地址:[2304.02643] Segment Anything (arxiv.org)
缺少的部分暂时不更,感觉不是那么重要。
语义分割
语义分割是对像素粒度的分类,是一种dense classification的任务。常用于医学与自动驾驶领域
语义分割的结果也可以作为对图像的抽象表达,提取更有代表性的特征,作为其他任务的输入。
语义分割数据集
PascalVOC
Cityscape(主要用于自动驾驶)
语义分割模型
FCN:可以适应任意输入大小。主要有基于UNet和基于带孔卷积两种类型。
U-Net:下采样丢掉冗余信息。
带孔卷积:conv与pool可以扩大感受野,减少计算量,提高特征的提成程度。但其过程本身就会丢失信息。带孔卷积不对输入进行密集采样,而是使用间隔若干位置采样的方式,在不丢失信息的前提下,提升感受野的大小,带来更好的信息提取能力。
Transformer+语义分割:ViT一开始感受野就是全局图像
交互式分割
交互式分割:由用户提供少量交互完成对目标物分割的操作。交互的种类可以有多种,包括点击(point),划线(text),画框(box)等。
为何要 ...
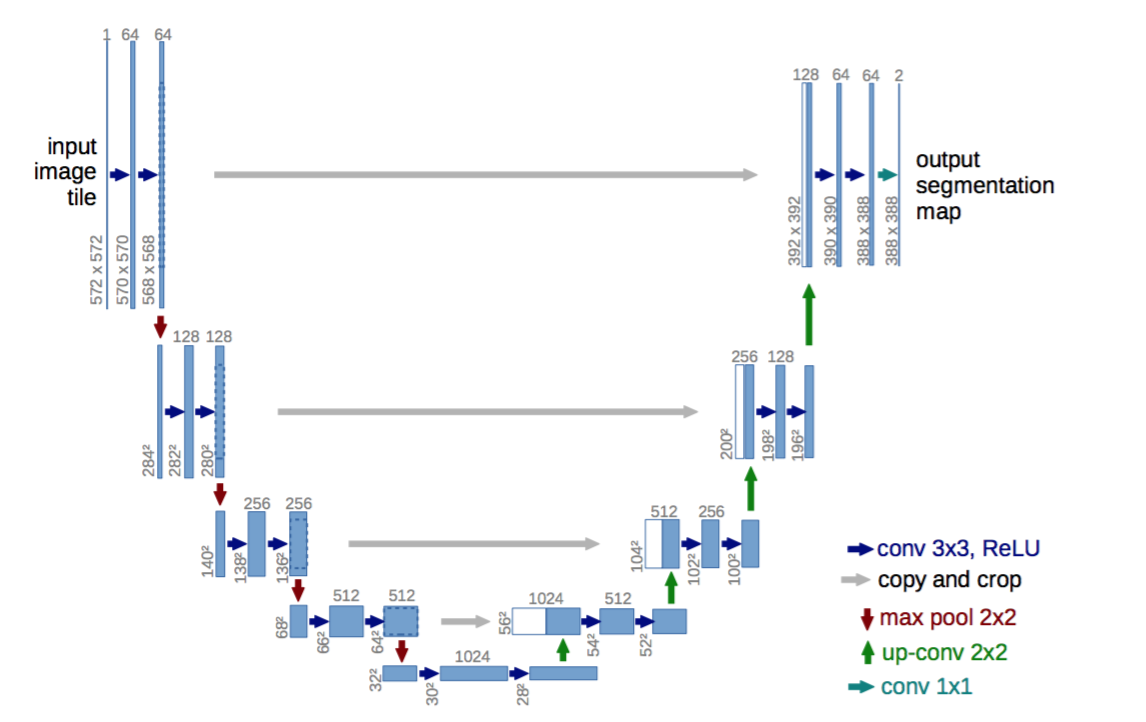
U-Net精读
原文:https://arxiv.org/pdf/1505.04597v1
参考:
从零开始的U-net入门_u net-CSDN博客
U-Net - Convolutional Networks 论文翻译——中英文对照-腾讯云开发者社区-腾讯云 (tencent.com)
FCN(全卷积神经网络)详解-CSDN博客
U-Net精读
创新点
提出了一种网络及训练策略,它依赖于大量使用数据增强,以便更有效地使用获得的标注样本。
这个架构包括捕获上下文的收缩路径和能够精确定位的对称扩展路径。
这种网络可以从非常少的图像进行端到端训练
1.引言
在生物医学图像处理中,期望的输出应该包括位置,即类别标签应该分配给每个像素。此外,生物医学任务中通常无法获得数千张训练图像。因此,Ciresan等人在滑动窗口设置中训练网络,通过提供像素周围局部区域(patch)作为输入来预测每个像素的类别标签。首先,这个网络可以定位。其次,局部块方面的训练数据远大于训练图像的数量。由此产生的网络大幅度地赢得了ISBI 2012EM分割挑战赛。
这样的]的策略有两个缺点。
首先,它非常慢,因为必须为每个图 ...




