
常见归一化方法(BN,LN,IN,GN)
BatchNorm
BatchNorm解决的问题
基础 | batchnorm原理及代码详解-CSDN博客
一方面但是,如果我们每一个batch输入的数据都具有不同的分布,显然会给网络的训练带来困难。另一方面,数据经过一层层网络计算后,其数据分布也在发生着变化,此现象称为Internal Covariate Shift,接下来会详细解释,会给下一层的网络学习带来困难。使得在较短的时间内使他们收敛更加棘手。批量规范化(batch normalization) (Ioffe and Szegedy, 2015),这是一种流行且有效的技术,可持续加速深层网络的收敛速度
Internal Covariate Shift
是google小组在论文https://arxiv.org/abs/1502.03167中提出来的,其主要描述的是:训练深度网络的时候经常发生训练困难的问题,因为,每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难。
covariate shift
Internal Covariate Shift发生在神经网络的 ...
深度学习基础(三)-过欠拟合,梯度消失爆炸,前反向传播...
深度学习基础(三)-过欠拟合,梯度消失爆炸,前反向传播…
小批量随机梯度下降
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)
在每次迭代中,我们首先随机抽样一个小批量B\mathcal{B}B, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数η\etaη,并从当前参数的值中减掉。
用下面的数学公式来表示这一更新过程(∂\partial∂表示偏导数)
(w,b)←(w,b)−η∣B∣∑i∈B∂(w,b)l(i)(w,b)(\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in ...
深度学习基础(二)-激活函数,损失函数,优化算法与参数管理
深度学习基础(二)-激活函数,损失函数,优化算法与参数管理
激活函数
激活函数有两类:饱和激活函数”和“非饱和激活函数”。sigmoid和tanh是“饱和激活函数”而ReLU及其变体则是“非饱和激活函数”。使用“非饱和激活函数”的优势在于两点:
首先,“非饱和激活函数”能解决所谓的“梯度消失”问题。
其次,它能加快收敛速度。
ReLU函数
ReLU提供了一种非常简单的非线性变换。 给定元素x,ReLU函数被定义为该元素与0的最大值:
ReLU(x)=max(x,0).{ReLU}(x) = max(x, 0).
ReLU(x)=max(x,0).
ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题
缺点:
训练的时候很脆弱,很容易就"死了"例如,一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元的梯度就永远都会是 0。如果 l ...
深度学习基础(一)-张量创建,计算与自动微分
深度学习基础(一)-张量创建,计算与自动微分
张量创建
1234567891011121314151617181920212223import torchx = torch.arrange(12)x = torch.arrange(12,dtype=torch.float32)x.shapex.numel() # 求元素个数x.reshape(3,4)torch.ones(a,b)torch.zeros(a,b)torch.randn(a,b)w = torch.normal(0, 0.01, size=(2,1), requires_grad=True) # 正态分布torch.tensor([]) # numpy 到 tensor的转换a, b, c, d = [torch.tensor(x, dtype=torch.float32) for x in [a, b, c, d]]torch.normal(均值,标准差,x.shape) # 要梯度更新的化torch.normal(均值,标准差,x.shape,require_grad=True)
张量计算
123456789 ...
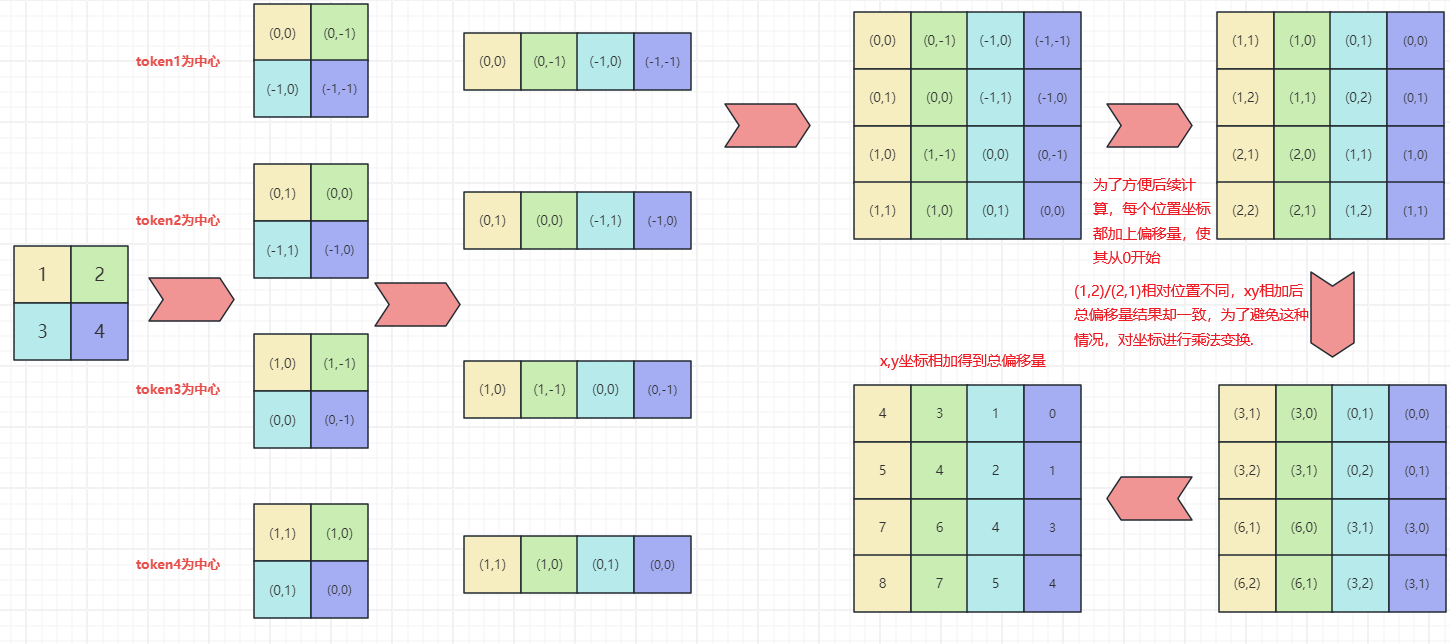
SwinTransformer代码详解
官方代码:https://github.com/microsoft/Swin-Transformer/
参考:论文详解:Swin Transformer - 知乎 (zhihu.com)
【深度学习】详解 Swin Transformer (SwinT)-CSDN博客
Swin Transformer 论文详解及程序解读 - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/401661320
AI大模型系列之三:Swin Transformer 最强CV图解(深度好文)_cv大模型-CSDN博客
整体架构
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110 ...
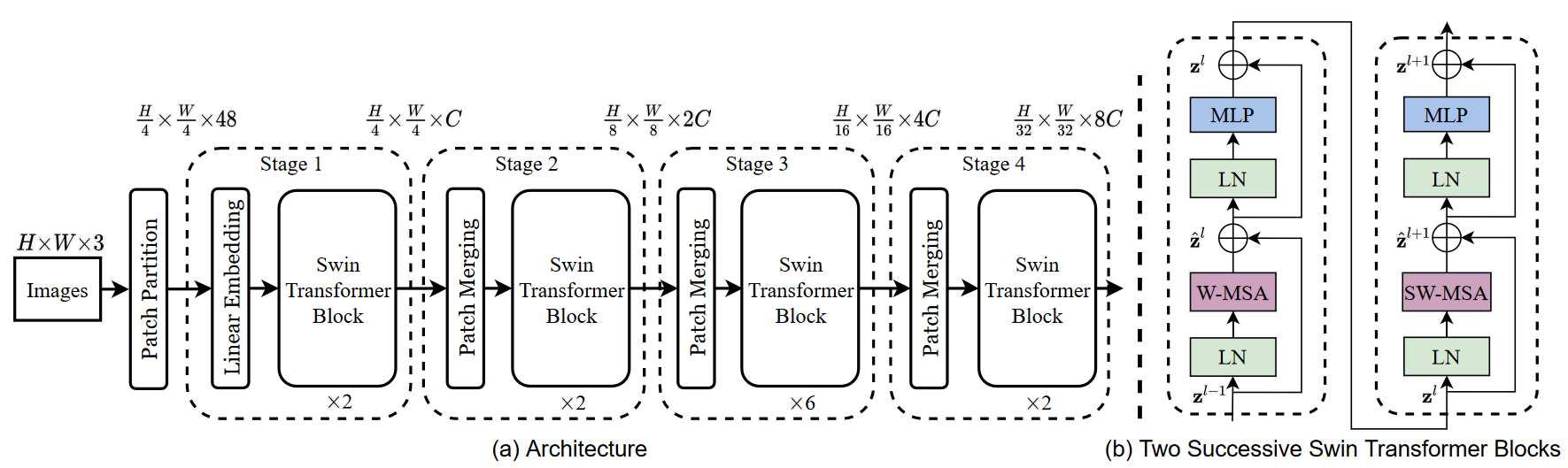
SwinTransformer论文精读
原文:https://arxiv.org/abs/2103.14030
参考:Swin Transformer论文精读【论文精读】哔哩哔哩_bilibili
Swin Transformer
摘要
本文提出了一种新的vision Transformer,称为 Swin Transformer,它能够作为计算机视觉领域的通用骨干网络。将 Transformer 从语言领域应用到视觉的挑战源于两个领域之间的差异,例如视觉实体规模的巨大差异(相同语义的实体在不同场景不同图像中尺寸差异大)以及图像中像素与文本中单词相比的高分辨率(以像素点为基本单位的话,序列长度会变得非常长)。为了解决这些差异,我们提出了一个分层 Transformer,其表示是使用 Shifted windows 计算得到的。移位窗口方案通过将自注意力计算限制在非重叠的本地窗口,同时还允许跨窗口连接,带来了更高的效率。这种层次结构非常灵活,能够提供各种层次的尺度信息,并且具有相对于图像大小线性增长的计算复杂性(注意力是在窗口内计算的)。 Swin Transformer 的这些品质使其能够兼容广泛的视觉任务,包括图像分类 ...
Diffusion课程(一)- 介绍
转载自:https://huggingface.co/learn/diffusion-course
概述
什么是扩散模型
扩散模型是对“生成模型”的算法的相对较新的补充。生成模型的目标是在给定大量训练示例的情况下学习如何生成数据,例如图像或音频。一个好的生成模型将创建一组类似于训练数据的多样化输出,而不是精确的副本。扩散模型如何实现这一目标?为了说明目的,让我们重点关注图像生成案例。
扩散模型成功的秘诀在于扩散过程的迭代性质。生成从随机噪声开始,但经过多个步骤逐渐细化,直到出现输出图像。在每一步中,模型都会估计我们如何从当前输入变为完全去噪的版本。然而,由于我们在每一步中只进行很小的更改,因此早期阶段(预测最终输出极其困难)的估计中的任何错误都可以在以后的更新中纠正。
与其他一些类型的生成模型相比,模型的训练相对简单。我们重复
从训练数据中加载一些图像。
添加不同数量的噪声。请记住,我们希望模型能够很好地估计如何“修复”(去噪)极其嘈杂的图像和接近完美的图像。
将图像的噪声版本输入模型。
评估模型在对这些输入进行去噪方面的表现 。
使用此信息来更新模型权重然后重复。
为了使用 ...
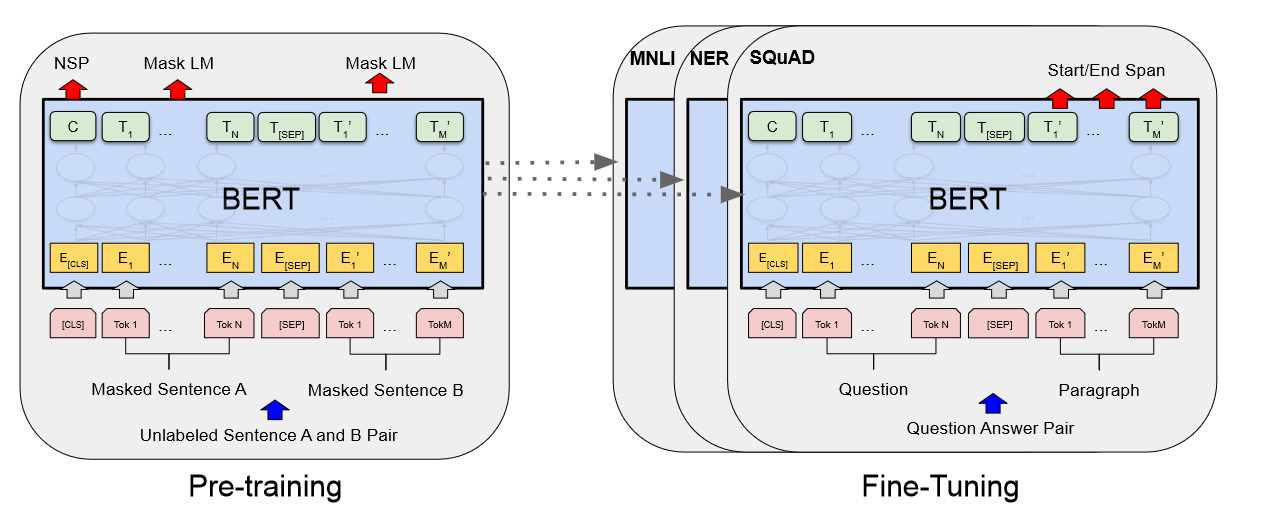
Bert原文笔记
摘要:
我们引入了一种名为 BERT 的新的语言表示模型,它代表 Transformers 的双向编码器表示。与最近的语言表示模型不同,BERT 旨在通过联合调节所有层中的左右上下文来预训练未标记文本的深度双向表示。因此,预训练的 BERT 模型只需一个额外的输出层即可进行微调,从而为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改。
BERT 概念简单,实验结果更好。它在 11 项自然语言处理任务上获得了最新的结果,包括将 GLUE 分数提高到 80.5%(绝对提高 7.7%)、MultiNLI 准确率提高到 86.7%(绝对提高 4.6%)、SQuAD v1.1问答测试 F1 达到 93.2(绝对提高 1.5 分),SQuAD v2.0 测试 F1 达到 83.1(绝对提高 5.1 分)。
1.介绍
语言模型的预训练已被证明可以有效改善许多自然语言处理任务。其中包括句子层面的任务,例如自然语言推理和释义,其目的是通过整体分析句子来预测句子之间的关系,以及token层面的任务,例如实体命名(人名,街道名字)的识别和问答,其中模型需要在token ...

使用hexo+github搭建个人博客
官方网址:Hexo
主题:Butterfly
主题美化:Butterfly主题美化教程
使用hexo+github搭建个人博客
前期准备安装
Nodejs
2024最新版Node.js下载安装及环境配置教程【保姆级】_nodejs下载-CSDN博客
Git
git安装配置教程(小白保姆教程2024最新版)_git安装及配置教程-CSDN博客
git的安装与配置教程-超详细版_git安装及配置教程-CSDN博客
之后
Hexo建站手册(详细教程) - 知乎 (zhihu.com)
使用 Hexo+GitHub 搭建个人免费博客教程(小白向) - 知乎 (zhihu.com)
使用hexo搭建github.io博客(一) - 诗&远方 - 博客园 (cnblogs.com)
HEXO系列教程 | 使用GitHub部署静态博客HEXO | 小白向教程 – 夜梦星尘の折腾日记 (yemengstar.com)
Hexo 博客搭建并部署到 GitHub Pages(2024最新详细版)_github pages上部署hexo-CSDN博客
Hexo+GitHub搭建个人博客教程 ...

NLP课程(七/一)- Token分类
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(7.1)- Token分类
我们将探索的第一个应用程序是令牌分类。这个通用任务包含任何可以表述为“为句子中的每个标记分配标签”的问题,例如:
命名实体识别(NER) :查找句子中的实体(例如人、位置或组织)。这可以表述为通过每个实体一个类和“无实体”一个类来为每个标记分配一个标签。
词性标注(POS) :将句子中的每个单词标记为对应于特定的词性(例如名词、动词、形容词等)。
分块:查找属于同一实体的标记。此任务(可以与 POS 或 NER 组合)可以表述为将一个标签(通常为B- )分配给位于块开头的任何标记,将另一个标签(通常为I- )分配给块内的标记,第三个标签(通常是O )表示不属于任何块的标记。
在本节中,我们将在 NER 任务上微调模型 (BERT)
数据准备
首先,我们需要一个适合标记分类的数据集。在本节中,我们将使用CoNLL-2003 数据集,其中包含来自路透社的新闻报道。
只要您的数据集由分 ...




