

NLP课程(六-下)- 逐块构建分词器
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(六-下)- 逐块构建分词器
逐块构建分词器
正如我们在前面几节中所看到的,标记化包括几个步骤:
规范化(任何认为必要的文本清理,例如删除空格或重音符号、Unicode 规范化等)
预标记化(将输入分割为单词)
通过模型运行输入(使用预先标记化的单词来生成标记序列)
后处理(添加分词器的特殊标记,生成注意掩码和标记类型 ID)
示例:
Tokenizers 库的构建是为了为每个步骤提供多个选项,您可以将它们混合和匹配在一起。在本节中,我们将了解如何从头开始构建分词器,而不是从旧分词器训练新的分词器。然后,您将能够构建您能想到的任何类型的标记器!
确地说,该库是围绕一个中心Tokenizer类构建的,其中的构建块在子模块中重新分组:
normalizers包含您可以使用的所有可能类型的Normalizer (完整列表请参见此处)。
pre_tokenizers包含您可以使用的所有可能的PreTokenizer ...
NLP课程(六-中)- 三种标记化
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(六-中)- 三种标记化
字节对编码标记化(BPE)
字节对编码(BPE)最初被开发为一种压缩文本的算法,然后在预训练 GPT 模型时被 OpenAI 用于标记化。许多 Transformer 模型都使用它,包括 GPT、GPT-2、RoBERTa、BART 和 DeBERTa。
1.训练算法
BPE训练算法首先计算语料库中使用的唯一单词集**(在完成标准化和预标记化步骤之后),**然后通过获取用于编写这些单词的所有符号来构建词汇表。一个非常简单的例子,假设我们的语料库使用了这五个词:
1"hug", "pug", "pun", "bun", "hugs"
基础词汇将是 ["b", "g", "h", "n", "p" ...
NLP课程(六-上)- Tokenizer库
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(六-上)- Tokenizer库
根据已有的tokenizer训练新的tokenizer
1.准备语料库
⚠️ 训练标记器与训练模型不同!模型训练使用随机梯度下降使每个batch的loss小一点。它本质上是随机的(这意味着在进行两次相同的训练时,您必须设置一些随机数种子才能获得相同的结果)。训练标记器是一个统计过程,它试图确定哪些子词最适合为给定的语料库选择,用于选择它们的确切规则取决于分词算法。它是确定性的,这意味着在相同的语料库上使用相同的算法进行训练时,您总是会得到相同的结果。
Transformers 中有一个非常简单的 API,你可以用它来训练一个新的标记器,使它与现有标记器相同的特征: AutoTokenizer.train_new_from_iterator()
首要任务是在训练语料库中收集该语言的大量数据。为了提供每个人都能理解的示例,我们在这里不会使用俄语或中文之类的语言,而是使用在特定 ...
NLP课程(五)- Datasets库
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(五)- Datasets库
在微调模型时有三个主要步骤:
从hugs Face Hub加载一个数据集。
使用Dataset.map()对数据进行预处理。
加载和计算指标(特征)。
数据集不在 Hub
Data format
Loading script
Example
CSV & TSV
csv
load_dataset("csv", data_files="my_file.csv")
Text files
text
load_dataset("text", data_files="my_file.txt")
JSON & JSON Lines
json
load_dataset("json", data_files="my_file.jsonl")
...
NLP课程(三)- 微调预训练模型
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(三)- 微调预训练模型
预处理数据
1. 加载数据集
以MRPC(微软研究释义语料库)数据集作为示例,该数据集由威廉·多兰和克里斯·布罗克特在这篇文章发布。该数据集由5801对句子组成,每个句子对带有一个标签,指示它们是否为同义(即,如果两个句子的意思相同)。
使用MRPC数据集中的GLUE 基准测试数据集,它是构成MRPC数据集的10个数据集之一,这是一个学术基准,用于衡量机器学习模型在10个不同文本分类任务中的性能。
通过以下的代码下载MRPC数据集:
123456789101112131415161718from datasets import load_datasetraw_datasets = load_dataset("glue", "mrpc")raw_datasetsDatasetDict({ train: Dataset({ ...
NLP课程(二)- Transformers的使用
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(二)- Transformers的使用
pipline的内部
示例:
123456789from transformers import pipelineclassifier = pipeline("sentiment-analysis")classifier( [ "I've been waiting for a HuggingFace course my whole life.", "I hate this so much!", ])
输出:
12[{'label': 'POSITIVE', 'score': 0.9598047137260437}, {'label': 'NEGAT ...
NLP课程(一)- 介绍
转载自:https://huggingface.co/learn/nlp-course/zh-CN/
原中文文档有很多地方翻译的太敷衍了,因此才有此系列文章。
NLP课程(一)- 介绍
常见NLP任务
常见 NLP 任务的列表,每个任务都有一些示例:
对整个句子进行分类: 获取评论的情绪,检测电子邮件是否为垃圾邮件,确定句子在语法上是否正确或两个句子在逻辑上是否相关
对句子中的每个词进行分类: 识别句子的语法成分(名词、动词、形容词)或命名实体(人、地点、组织)
生成文本内容: 用自动生成的文本完成提示,用屏蔽词填充文本中的空白
从文本中提取答案: 给定问题和上下文,根据上下文中提供的信息提取问题的答案
从输入文本生成新句子: 将文本翻译成另一种语言,总结文本
pipline()函数
推理pipeline (huggingface.co)
Transformers能做什么? - Hugging Face NLP Course
Transformers 库中最基本的对象是 pipeline() 函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够通过直接输入任何文本并 ...
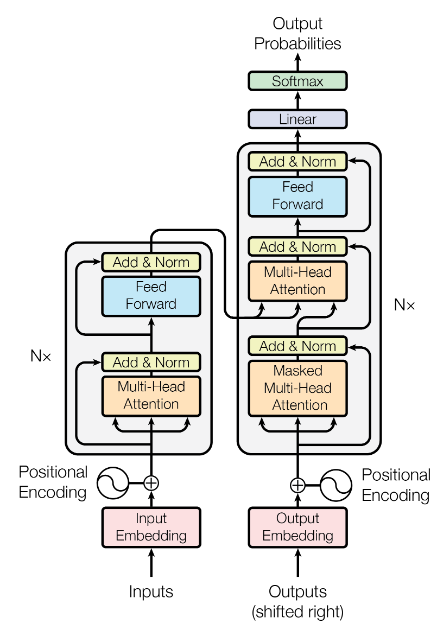
Transformer原文笔记
Transformer原文笔记
Transformer中Self-Attention以及Multi-Head Attention详解_哔哩哔哩_bilibili
详解Transformer中Self-Attention以及Multi-Head Attention_transformer multi head-CSDN博客
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
摘要
主要序列转导模型基于复杂的循环或卷积神经网络,包括编码器和解码器。性能最好的模型还通过注意力机制连接编码器和解码器。我们提出了一种新的简单网络架构——Transformer,它完全基于注意力机制,完全不需要递归和卷积。对两个机器翻译任务的实验表明,这些模型具有卓越的质量,同时具有更高的并行性,并且需要的训练时间显着减少。我们的模型在 WMT 2014 英德翻译任务中获得了 28.4 BLEU,比现有的最佳结果(包括集成)提高了 2 BLEU 以上。在 WMT 2014 英法翻译任务中,我们的模型在8个GPU上训练3.5天后,建立了新的单模型最先进 BLEU分数41.8,这只是最佳模型 ...
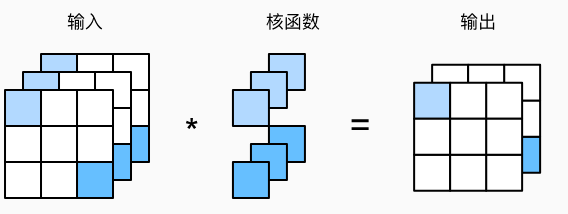
现代卷积神经网络(1)-基础
卷积神经网络
基本介绍
到目前为止,我们处理这类结构丰富的数据的方式还不够有效仅仅通过将图像数据展平成一维向量而忽略了每个图像的空间结构信息,再将数据送入一个全连接的多层感知机中。 因为这些网络特征元素的顺序是不变的,因此最优的结果是利用先验知识,即利用相近像素之间的相互关联性,从图像数据中学习得到有效的模型。
卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。现代卷积神经网络的设计得益于生物学、群论和一系列的补充实验。 卷积神经网络需要的参数少于全连接架构的网络,而且卷积也很容易用GPU并行计算。
图像中本就拥有丰富的结构,而这些结构可以被人类和机器学习模型使用卷积神经网络正是将空间不变性(spatial invariance)的这一概念系统化,从而基于这个模型使用较少的参数来学习有用的表示。
适合于计算机视觉的神经网络架构:
平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
局部 ...
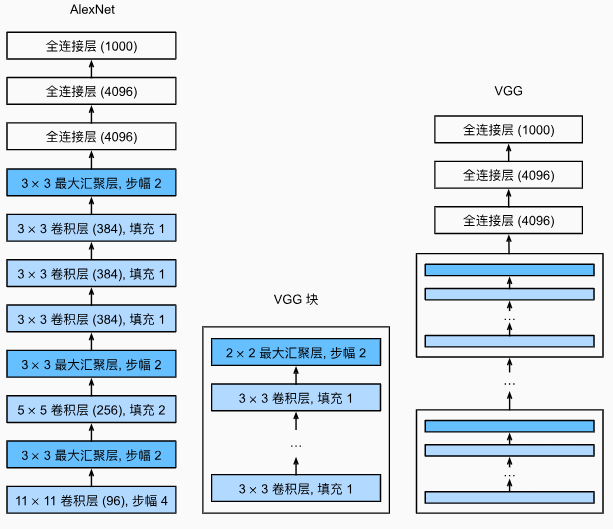
现代卷积神经网络(8)-VGG
使用块的网络(VGG)
经典卷积神经网络的基本组成部分是下面的这个序列:
带填充以保持分辨率的卷积层;
非线性激活函数,如ReLU;
汇聚层,如最大汇聚层。
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。使用块的想法首先出现在牛津大学的视觉几何组(visual geometry group)的VGG网络中。通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
导入库,定义VGG块
123456789101112131415import torchfrom torch import nnfrom d2l import torch as d2ldef vgg_block(num_convs, in_channels, out_channels): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels, ...




