
现代卷积神经网络(4)-ResNet
残差网络(ResNet)
来源
对于非嵌套函数类,较复杂(由较大区域表示)的函数类不能保证更接近“真”函数( f∗f^∗f∗ )。这种现象在嵌套函数类中不会发生。
为了接近真函数 f∗f^∗f∗,在集合FiF_iFi中找最接近真函数的函数,但如果是非嵌套函数类,不一定找到的最接近的函数越来越接近真函数,故若新的集合包含原来的集合,可以保证每次找到的新的函数更接近真函数。所以神经网络模型如果包含先前层的部分,效果会更好。
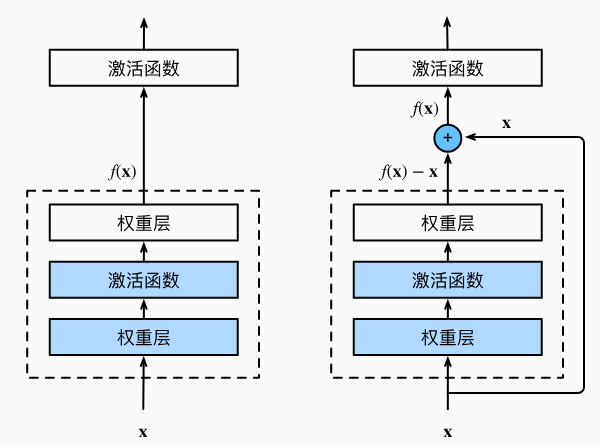
因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。 对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)f(x)=x,新模型和原模型将同样有效。 同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。何恺明等人提出了残差网络(ResNet) (He et al., 2016)。 残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
残差块
图虚线框中的部分则需要拟合出残差映射f(x)−x。 残差映射在现实中往往更容易优化。 以本节开头提到的恒等映 ...
现代卷积神经网络(7)-网络中的网络(NiN)
网络中的网络(NiN)
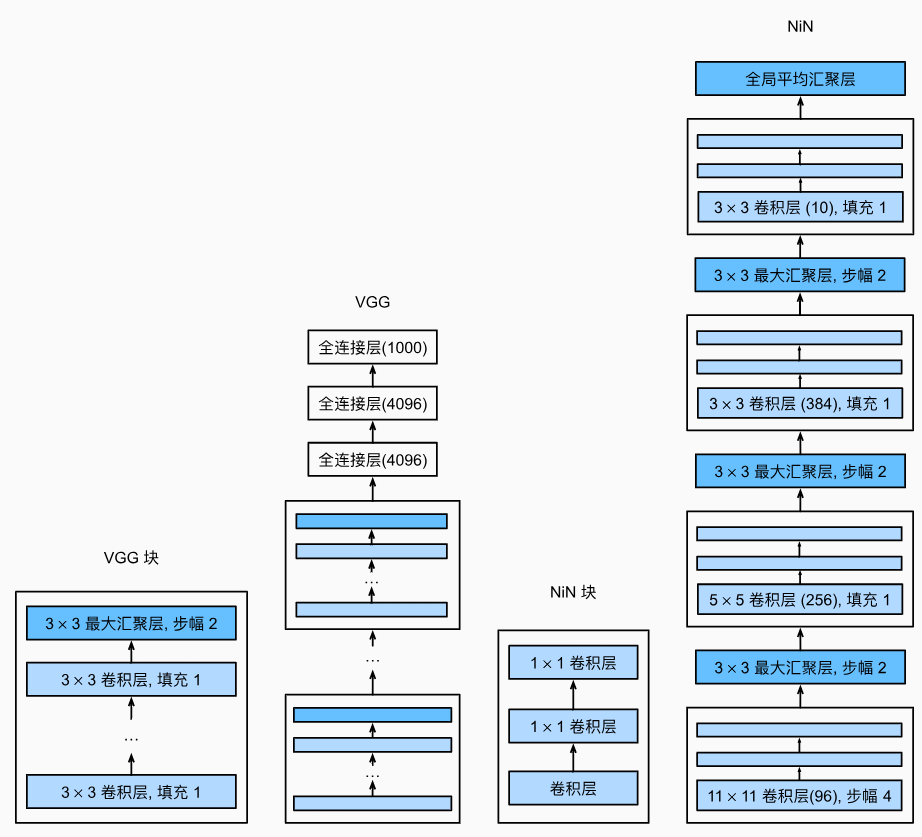
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。 AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。 或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。 **网络中的网络(NiN)**提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机。
全连接层的输入和输出通常是分别对应于样本和特征的二维张量。 <NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。 如果我们将权重连接到每个空间位置,我们可以将其视为1×1卷积层(如 6.4节中所述),或作为在每个像素位置上独立作用的全连接层。 从另一个角度看,即将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)。
NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。 相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global averag ...
现代卷积神经网络(2)-LeNet
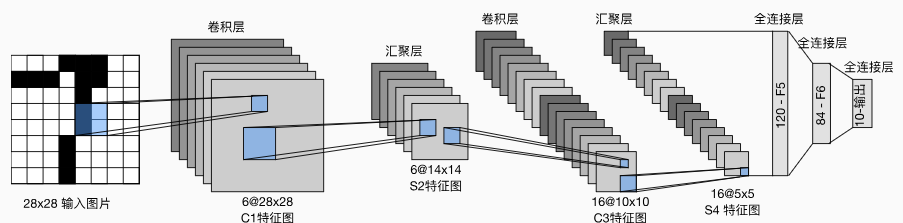
LeNet
导入库,定义模型
1234567891011121314151617181920212223import torchfrom torch import nnfrom d2l import torch as d2lfrom torchvision import transformsfrom torch.utils import datanet = nn.Sequential( nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(), nn.Linear(120, 84), nn.Sigmoid(), nn.Li ...
现代卷积神经网络(6)-GoogleNet
含并行连结的网络(GoogLeNet)
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。 这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。 毕竟,以前流行的网络使用小到1×1,大到11×11的卷积核。 本文的一个观点是,有时使用不同大小的卷积核组合是有利的。
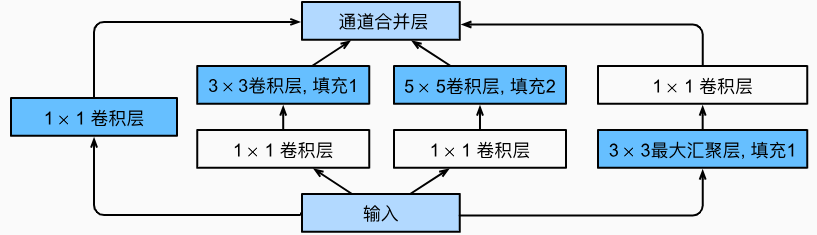
Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用1×1卷积层减少每像素级别上的通道维数从而降低模型复杂度。
GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
导入库,定义Inception块
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)
Inception块由四条并行路径组成。 前三条路径使用窗口大小为1×1、3×3和5×5的卷积 ...
现代卷积神经网络(5)-DenseNet
稠密连接网络(DenseNet)
深度学习——稠密连接网络(DenseNet)原理讲解+代码(torch)-CSDN博客
稠密连接网络(DenseNet)在某种程度上是ResNet的逻辑扩展
任意函数的泰勒展开式(Taylor expansion),它把这个函数分解成越来越高阶的项。在x接近0时
f(x)=f(0)+f′(0)x+f′′(0)2!x2+f′′′(0)3!x3+….f(x) = f(0) + f'(0) x + \frac{f''(0)}{2!} x^2 + \frac{f'''(0)}{3!} x^3 + \ldots.
f(x)=f(0)+f′(0)x+2!f′′(0)x2+3!f′′′(0)x3+….
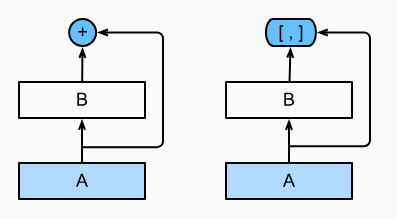
ResNet将f分解为两部分:一个简单的线性项和一个复杂的非线性项。 如果想将f拓展成超过两部分的信息, 一种方案便是DenseNet
ResNet和DenseNet的关键区别在于,DenseNet输出是连接(用图中的[,]表示)而不是如ResNet的简单相加。 因此,在应用越来越复杂的函数序列后 ...
现代卷积神经网络(3)-AlexNet
AlexNet
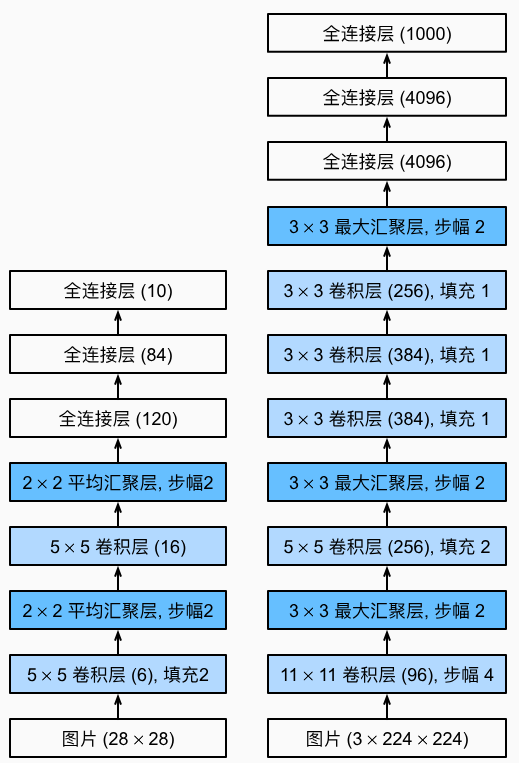
LeNet(左)AlexNet(右)
AlexNet与LeNet的比较
AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
AlexNet使用ReLU而不是sigmoid作为其激活函数。一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。
AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
导入库,定义模型
1234567891011121314151617181920212223242526272829303132333435363738import torchfrom ...
ViT原文笔记
原论文地址:https://arxiv.org/abs/2010.11929
代码地址:GitHub - google-research/vision_transformer
参考博客:
【深度学习】详解 Vision Transformer (ViT)-CSDN博客
深度学习之图像分类(十八)-- Vision Transformer(ViT)网络详解_vit网络-CSDN博客
参考视频:ViT论文逐段精读【论文精读】_哔哩哔哩_bilibili
绿色及引用:非原文内容,理解部分
红色:个人认为原文中需要特别注意的地方
摘要
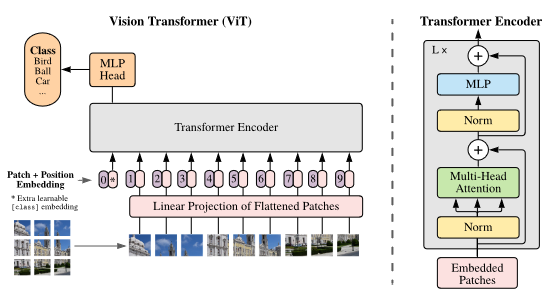
虽然 Transformer 架构已成为 NLP 任务的事实标准,但它在 CV 中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们证明了这种对 CNNs 的依赖是不必要的,直接应用于图像块序列 (sequences of image patches) 的纯 Transformer 可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 (ImageNet、CIFA ...

标准位置编码,旋转位置编码与线性偏差注意力
转载自:https://blog.csdn.net/v_JULY_v/article/details/134085503
位置编码
第一部分 transformer原始论文中的标准位置编码
如此篇文章《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》所述,RNN的结构包含了序列的时序信息,而Transformer却完全把时序信息给丢掉了,比如“他欠我100万”,和“我欠他100万”,两者的意思千差万别,故为了解决时序的问题,Transformer的作者用了一个绝妙的办法:位置编码(Positional Encoding)
1.1 标准位置编码的起源
即将每个位置编号,从而每个编号对应一个向量,最终通过结合位置向量和词向量,作为输入embedding,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了,具体怎么做呢?
如果简单粗暴的话,直接给每个向量分配一个数字,比如1到1000之间
也可以用one-hot编码表示位置
transformer论文中作者通过sin函数和cos函数交替来创建 p ...




